大数据概论笔记4 Hadoop架构与大数据存储的数据处理及存储支持服务
一、Hadoop架构概述
Hadoop是一个由Apache基金会开发的分布式系统基础架构,其核心设计思想源自Google的MapReduce和Google File System(GFS)论文。它旨在通过一个高度可扩展的、可靠的、容错的分布式计算框架,来处理海量数据集(通常达到TB甚至PB级别)。Hadoop的核心优势在于其能够将计算任务和数据存储分布在由成百上千台普通商用服务器组成的集群中,从而实现高效并行处理。
Hadoop生态系统主要由以下几个核心组件构成:
- Hadoop Common(公共模块):提供支持其他Hadoop模块的通用工具和库。
- Hadoop Distributed File System (HDFS):分布式文件系统,是Hadoop的存储基石。
- Hadoop YARN (Yet Another Resource Negotiator):资源管理与作业调度框架,负责集群资源的管理和分配。
- Hadoop MapReduce:基于YARN的分布式并行计算编程模型和框架。
二、大数据存储核心:HDFS详解
HDFS是专为存储超大文件、运行在商用硬件集群上而设计的文件系统。其核心设计目标包括:高容错性、高吞吐量访问、流式数据访问模式以及处理大规模数据集。
1. 架构与关键角色
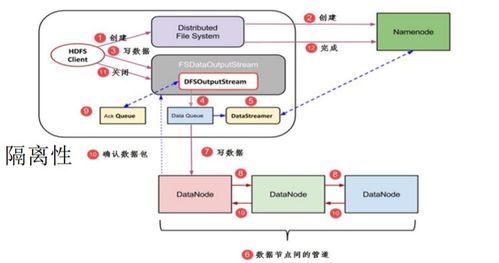
NameNode(主节点):
管理文件系统的命名空间(如目录树、文件元数据:文件名、副本数、权限、数据块位置映射等)。
- 不存储实际数据,只存储元数据。
- 是整个系统的“大脑”,其单点故障曾是早期版本的瓶颈,后期通过HA(高可用)方案解决。
- DataNode(从节点):
- 存储实际的数据块(Block,默认大小128MB)。
- 负责执行来自客户端的读写请求,并定期向NameNode发送心跳和数据块报告。
- Secondary NameNode(辅助节点,非热备):
- 定期合并NameNode的编辑日志(edits)和镜像文件(fsimage),以缩短NameNode重启时间,但不能直接接管NameNode的工作。
2. 数据存储机制
分块存储:大文件被切分成固定大小的数据块(Blocks),这些块被分散存储在不同的DataNode上,便于并行处理。
多副本冗余:每个数据块默认会被复制成3个副本(可配置),存储在不同的机架或节点上。这提供了极高的数据可靠性,即使个别节点或机架失效,数据也不会丢失。
* 机架感知:Hadoop能感知网络拓扑,会智能地将副本放置在不同的机架上,以平衡数据可靠性、写入带宽和读取性能。
三、数据处理核心:MapReduce与YARN
1. MapReduce 编程模型
MapReduce是一种简化分布式计算的编程模型,将计算过程抽象为两个主要阶段:
Map(映射)阶段:输入数据被分割成独立的块,由多个Map任务并行处理,生成一系列中间键值对(key-value pairs)。
Reduce(归约)阶段:将Map阶段输出的所有中间键值对,按照键进行排序和分组,然后由多个Reduce任务并行处理,最终合并生成结果。
这种“分而治之”的思想,使得程序员无需关心分布式计算的底层细节(如数据分发、任务调度、容错),只需专注于实现Map和Reduce函数。
2. YARN 资源调度框架
在Hadoop 2.0之后,YARN取代了旧的MapReduce引擎中的JobTracker/TaskTracker架构,成为集群的“操作系统”,负责资源管理和作业调度。
ResourceManager (RM):全局资源管理器,负责整个集群的资源(CPU、内存)管理和分配。
NodeManager (NM):每个节点上的代理,负责管理单个节点上的资源,并执行来自RM的指令。
* ApplicationMaster (AM):每个应用程序(如一个MapReduce作业)专属的管理者,负责向RM申请资源,并与NM协作来监控和调度具体的任务(如Map Task, Reduce Task)。
YARN的解耦设计使得Hadoop生态系统不再局限于MapReduce一种计算框架,可以支持Spark、Flink、Tez等多种计算模型,极大地提升了集群的通用性和资源利用率。
四、数据处理和存储的支持服务
围绕Hadoop核心,一个庞大的生态系统提供了丰富的数据处理、存储和管理支持服务,主要包括:
1. 数据仓库与查询类
Hive:基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的查询语言(HiveQL)。Hive会将查询语句转换为MapReduce、Tez或Spark任务在集群上执行,降低了使用Hadoop进行数据分析的门槛。
Impala / Presto:提供基于MPP(大规模并行处理)架构的实时交互式SQL查询引擎,相比Hive的批处理模式,它们能实现秒级甚至亚秒级的查询响应,适用于即席查询。
2. 非结构化数据处理与NoSQL存储
* HBase:构建在HDFS之上的分布式、可扩展的列式NoSQL数据库。它支持海量数据的随机、实时读写访问,弥补了HDFS仅支持顺序批处理的不足。常用于需要快速查询大量稀疏数据的场景。
3. 数据采集与传输类
Sqoop:用于在Hadoop(HDFS/Hive/HBase)和传统关系型数据库(如MySQL, Oracle)之间高效传输批量数据的工具。
Flume:一个高可靠、高可用的分布式海量日志采集、聚合和传输系统,擅长从各种数据源(如Web服务器日志)实时收集数据并写入HDFS或HBase。
* Kafka:分布式流式数据平台,作为高吞吐量的消息队列,常用于构建实时数据管道和流式应用,是连接数据生产者和消费者(如Spark Streaming, Flink)的枢纽。
4. 工作流调度与管理
* Oozie:一个用于管理和调度Hadoop作业的工作流调度系统,可以将多个MapReduce、Hive、Pig、Sqoop等任务组合成一个复杂的工作流,并按照时间或数据依赖关系自动执行。
5. 资源协调与配置管理
* ZooKeeper:一个分布式的、开源的协调服务,为分布式应用提供一致性服务,如配置维护、命名服务、分布式同步、集群管理等。Hadoop的HA(如NameNode的故障自动切换)就依赖于ZooKeeper。
###
Hadoop以其HDFS(存储) 和 YARN/MapReduce(计算) 为核心,构建了一个稳固的大数据处理基础架构。其生态系统中丰富的支持服务,如Hive、HBase、Sqoop、Flume等,共同构成了一个完整的大数据解决方案栈,覆盖了从数据采集、存储、处理到分析的全生命周期,为企业应对海量、多样、高速增长的数据挑战提供了强大的技术支撑。理解Hadoop的架构及其生态系统,是掌握大数据技术的基石。
如若转载,请注明出处:http://www.zdchumei.com/product/59.html
更新时间:2026-06-19 10:03:32