Java手写HttpServer(201) 封装Request、储存参数与处理中文乱码
在Java手写HttpServer的开发中,封装Request对象、正确储存请求参数以及处理中文乱码是核心且关键的步骤。本文将通过一个实践案例,详细解析如何实现这些功能,并分享相关数据处理与存储的支持服务。
一、封装Request对象
Request对象是对HTTP请求的抽象封装,其主要职责是解析原始的HTTP请求报文,提取请求行、请求头和请求体等信息,并以更友好的方式提供给业务逻辑使用。
- 核心结构:一个基础的Request类应包含以下属性:
method: 请求方法(如GET、POST)。
url: 请求的URL。
version: HTTP协议版本。
headers: 存储所有请求头的Map。
parameters: 存储所有请求参数的Map(这是本次封装的重点)。
- 初始化与解析:在构造函数中,传入原始的
InputStream,并按HTTP协议规范逐行读取和解析。
- 首先解析请求行,分割出方法、URL和版本。
- 然后解析请求头,存入Map。
- 根据请求方法(如POST或有查询字符串的GET)解析请求体或URL中的参数。
二、储存请求参数与处理中文
参数的正确储存和编码处理是保证服务器功能正常的基础,尤其是对于中文参数。
- 参数存储:我们将解析后的参数键值对存储在一个
Map<String, String>或Map<String, List<String>>(考虑到同一参数名可能有多个值)中。关键步骤在于参数解析:
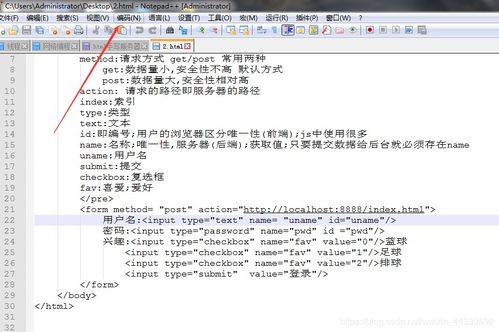
- GET请求:参数位于URL的查询字符串中(
?之后),如/login?username=张三&age=20。需要对URL进行分割和URL解码。
- POST请求(表单):参数位于请求体中,内容类型通常为
application/x-www-form-urlencoded。需要从InputStream中读取指定长度(由Content-Length头指定)的字节流,然后进行解析和URL解码。
- 处理中文乱码:乱码产生的根本原因是字节流到字符串转换时编码不一致。HTTP协议中,参数在传输时是经过URL编码(百分号编码)的。
- 核心解决方案:在将参数字节流或字符串存入Map之前,必须使用
URLDecoder.decode()方法进行解码。
* 关键代码示例:
`java
// 假设 paramStr 是像 "username=%E5%BC%A0%E4%B8%89" 这样的字符串
String decodedValue = URLDecoder.decode(paramStr, "UTF-8"); // 解码后得到 "张三"
parameters.put(key, decodedValue);
`
- 注意事项:确保解码时使用的字符集(如UTF-8)与客户端编码保持一致。现代应用普遍使用UTF-8。
三、实践练习与数据处理支持
理论结合实践方能巩固。你可以根据上述思路,动手实现一个能够接收GET/POST请求、并正确打印出中文参数的简易HttpServer。
在更复杂的业务场景中,涉及数据的持久化存储、业务逻辑处理等,可以考虑:
- 服务层抽象:在Request/Response封装之上,构建业务逻辑处理层(Service)。
- 数据存储支持:根据需求选择数据存储方案,例如:
- 使用
ArrayList、HashMap等进行内存存储,适用于临时数据或测试。
- 集成JDBC连接MySQL、PostgreSQL等关系型数据库进行持久化。
- 使用Redis等NoSQL数据库提供高速缓存服务。
- 通过文件IO操作将数据存储到本地文件。
四、
通过封装Request对象,我们实现了HTTP协议细节的隐藏,使业务开发更聚焦。正确处理参数存储和中文解码,是Web服务器能稳健处理用户输入的前提。这个手写过程能极大地加深你对HTTP协议、Java网络编程及编码问题的理解。
(注:本文内容来源于技术学习与,更多详细代码示例、分步教程及讨论,可参考相关技术博客社区。技术交流可关注相关平台账号。)
如若转载,请注明出处:http://www.zdchumei.com/product/50.html
更新时间:2026-06-19 16:50:50